●この記事のポイント
・名古屋大学が日本語対応の全二重音声対話システム「J-Moshi」を開発
・AIの音声対話性能を飛躍的に高め、まるで人間のような音声対話を実現
・コールセンターや接客など、さまざまな領域での活用に期待
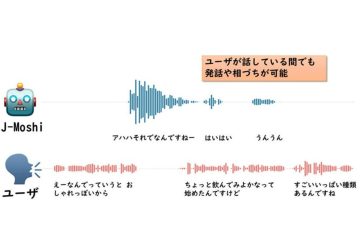
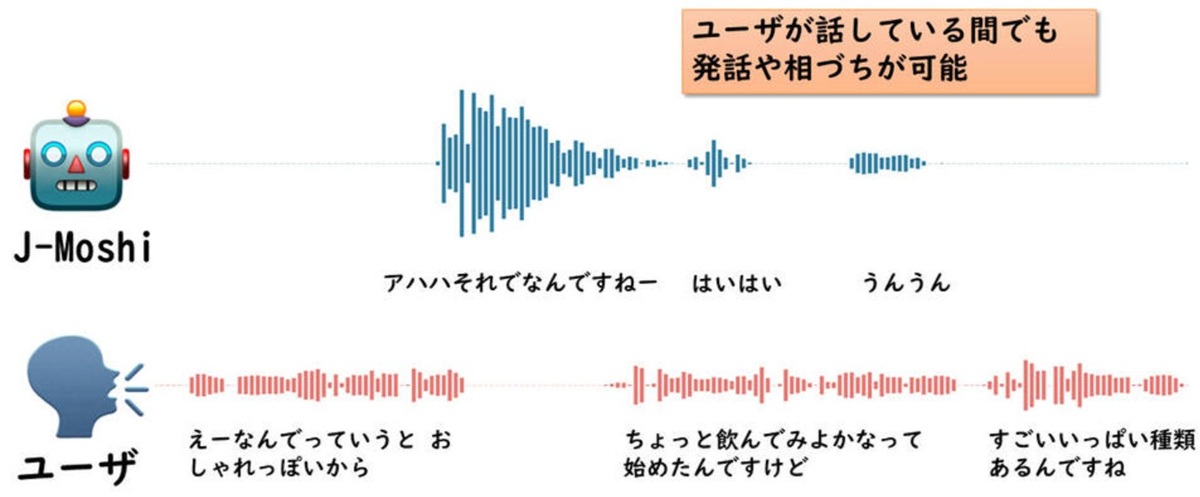
名古屋大学大学院情報学研究科の東中竜一郎教授の研究グループは、相手の話を聞きながら話すことのできる、世界初の日本語で利用可能なFull-duplex音声対話モデル「J-Moshi」を開発した。日本語による対話には「ええ」「なるほど」「はい」といった“相づち”が頻繁に入るため、英語と比較して自然な音声対話システムの実現は技術的に難しい。J-MoshiはAIの音声対話性能を飛躍的に高めることに成功し、人間同士の対話における発話のオーバーラップや相づちなど、同時双方向的な対話、まるで人間のような音声対話を実現。雑談や接客など、さまざまな場面での利用が期待されるという。J-Moshiが秘める可能性について、東中教授に取材した。
●目次
「誰がいつ喋るか」の課題を解決
対話システムの開発において、最も重要な課題となっていたのが「ターンテイキング」の問題だった。
「対話システムの開発には結構長い歴史があり、音声認識や音声合成の性能も向上してきましたが、人間のようなやり取りができないというのは大きな課題でした。一番の問題はターンテイキングであり、“誰がいつ喋るのか”という部分を、いかに人間らしくするのかという点でした。
従来の対話システムでは、音声認識をして、何を言うか考え、ターンを取るかどうかを判断してから音声合成を行うという段階的な処理を行っていました。しかし、この方法では、どうしてもトランシーバーのような対応になってしまうという限界がありました」
この問題を解決するため、J-Moshiでは世界的な潮流となっている新しいアプローチを採用した。
「最近では音声を直接モデル化するという方法が世界的な潮流になってきています。“音声認識して、考えて、喋る”というやり方ではなく、そこまでの音声から次にシステムが出すべき音声を直接生成するというアプローチです。
この手法により、従来のような段階的な処理ではなく、“音声から直接、次に喋るか黙るかも含めて判断することができる”ため、トランシーバーのようにならずに自然な対話が実現できるのです。結果として、ターンテイキングだけでなく音声の自然さも向上しました。会話の流れから何を、どういう声を出すかを予測しているので、声の出し方も非常に自然になり、人間らしいインタラクションになります」
データ準備が最大のハードル
開発において課題となったのは、データの準備だったという。
「全体的に7万時間分ほどの音声データを使っていますが、綺麗なデータは非常に少ないのです。2チャンネルの音声で、例えば左側のチャンネルに話者A、右側に話者Bが入っているような音声データというのは、それほど多くありません。J-Moshiでは、数百時間の独自収集データに加え、東京大学が公開している大規模データを活用しました。そのデータを扱えるようにするための前処理にも労力を要しました。音声認識や音と単語の対応付けなど、何万時間の音声データに対する地道な作業が必要でした。名古屋大学は大規模計算機クラスターを持っており、百台を超えるGPUマシンを使った学習環境が整っていたことも成功の要因となりました」
主にどのような領域での実用化が想定されるのか。
「基本的には対話システムが入っているところであれば、全てに活用できると思います。今の対話システムは、いつ話していいか分かりにくいので話しにくいという問題を抱えています。少し話したら急に動き出してしまったり、急に話が止まってしまったりというケースがよくあります。
例えばコールセンターでの顧客対応では、お客さんのクレーム対応であるとか、一般的な問い合わせ対応では、人間のような速いやり取りが重要になってくるため、従来のトランシーバー型では効率が悪く、顧客満足度の面でも課題がありました。
接客やカウンセリングなどの分野でも活用が期待され、AIで置き換えたいというニーズがあります。本技術は、人間の技量のほうが圧倒的に高いという現状を変える技術として注目されています」
GPTの進化のように段階的に改良
現在のJ-Moshiはプロトタイプ版で、研究用データを使用しているため商用利用にはハードルがある。そこで、商用化に向けた取り組みが進んでいる。
「国立情報学研究所に日本語の大規模言語モデルをつくる国のプロジェクト、LLM-jpがあり、そのなかで商用利用が可能な音声モデルを作っていくプロジェクトを立ち上げました。今年度中にはJ-Moshiと同等レベルのものを商用で利用できるようなかたちに持ってきたいと考えています。
1年目で商用利用可能なバージョンを開発し、2~3年目には制御性を高めて特定のタスクや業務に対応できるよう性能向上を図っていく予定です。現在のシステムは数分ぐらいしか持たないため、特定の業務にカスタマイズすることも難しいですが、初期の大規模言語モデルに近い段階から、GPTの進化のように段階的に改良していく方針です」
(文=BUSINESS JOURNAL編集部、協力=東中竜一郎/名古屋大学大学院教授)