
●この記事のポイント
アルファベットの2026年Q1決算は売上高1099億ドル・純利益81%増という記録的な数字を叩き出した。グーグルクラウドは63%増・受注残高4600億ドル超に急拡大し、AIインフラ企業への転換が鮮明だ。一方、英CMAが義務化を求める「AIオプトアウト」は新興勢力の参入障壁を高め、皮肉にもグーグルの独占を強化する可能性がある。
「AIの台頭でグーグル検索は不要になる」――そんな悲観論が市場で囁かれて久しい。だが4月29日(現地時間)に発表されたアルファベット(グーグルの親会社)の2026年1〜3月期決算は、その見立てを一蹴するものだった。
売上高は前年同期比22%増の1099億ドル(約17兆3000億円)。純利益は81%増の626億ドル(約9兆8000億円)。1株当たり利益(EPS)は5.11ドルと、市場予想の2.62ドルをほぼ倍で上回った。最後に二桁成長を記録したのは2022年のこと——その後もこれが11四半期連続の維持となる。「怪物決算」と呼ぶほかない数字だ。
なかでも際立つのがグーグルクラウドの爆発的成長だ。売上高は63%増の200億ドル(約3兆1400億円)と初めて200億ドルの大台を突破。さらにCFOのアナット・アシュケナージ氏は、クラウド事業の受注残高(バックログ)がこの1四半期だけでほぼ倍増し、4600億ドル超に達したと明かした。これは確定した「将来の売上」の積み上げを意味し、グーグルクラウドがいかに企業の基幹インフラとして浸透しているかを如実に示す。
広告収入も堅調で、グーグル検索・その他の広告は19%増の604億ドル。ユーチューブ広告も11%増の99億ドルに拡大した。サンダー・ピチャイCEOは決算発表でこう述べている。「検索クエリ数は過去最高を更新し、AIへの投資はビジネスのあらゆる領域で成長を牽引している」。
●目次
- 「AI無断学習」への包囲網が、逆にグーグルを利する「皮肉なパラドックス」
- 「検索会社」から「AIインフラ地主」へ——ビジネスモデルの静かなる変質
- CMAが本当に狙うのは「検索支配」と「AIデータ権」の切り離し
- 日本企業が直視すべき「データ格差」の正体
「AI無断学習」への包囲網が、逆にグーグルを利する「皮肉なパラドックス」
この「怪物決算」の翌日、ある重要な規制動向が改めて注目を集めている。英国の競争・市場庁(CMA)が1月28日に公表した、グーグルへの行動要件(Conduct Requirements)案だ。
内容を要約すると、①出版社がコンテンツを「AIオーバービュー(AI概要)」の学習・表示に使わせないよう拒否できる権利の保証、②そのオプトアウトを選択した出版社を、通常の検索順位において不利に扱ってはならない——という2点が柱となっている。
背景には深刻な問題がある。現状でコンテンツをAIオーバービューに使われないようにする唯一の手段(nosnippetタグ)を使うと、通常の検索流入が約45%減少するという調査結果が出ている。CMAはこれを「出版社にとって現実的な選択肢が存在しない」状態と認定。2025年10月にグーグルを検索市場における「戦略的市場地位(SMS)」保有者に指定し、制度的な介入の根拠を整えた。
一見するとこの規制は、グーグルにとって痛手のように映る。だが、視点を変えると異なる構図が浮かぶ。
データ経済学の観点から見ると、オプトアウトの法制化は「コンテンツの有料化」を促す制度的インフラとなりうる。 データを使ってほしいなら、対価を払え——この論理が正当化されると、AI学習に必要な高品質データへのアクセスには相応の資金力が求められる。年間純利益が2000億ドル(約31兆円)規模に達しようとしているグーグルのような企業は、その対価を払える。しかし資金力に乏しいAIスタートアップには、学習データそのものへのアクセスが事実上困難になる。
デジタル法制を専門とする英国の競争法研究者は次のように指摘する。
「規制が参入障壁を高める逆説は珍しくない。データの有料化が進めば、既存の巨大プラットフォームこそが最も安定的なデータ調達力を持つ。新興勢力には、規制強化がむしろ競争上の不利として働くリスクがある」
「検索会社」から「AIインフラ地主」へ——ビジネスモデルの静かなる変質
今回の決算が明示するのは、グーグルのビジネスモデルが静かに、しかし構造的に変容しているという事実だ。
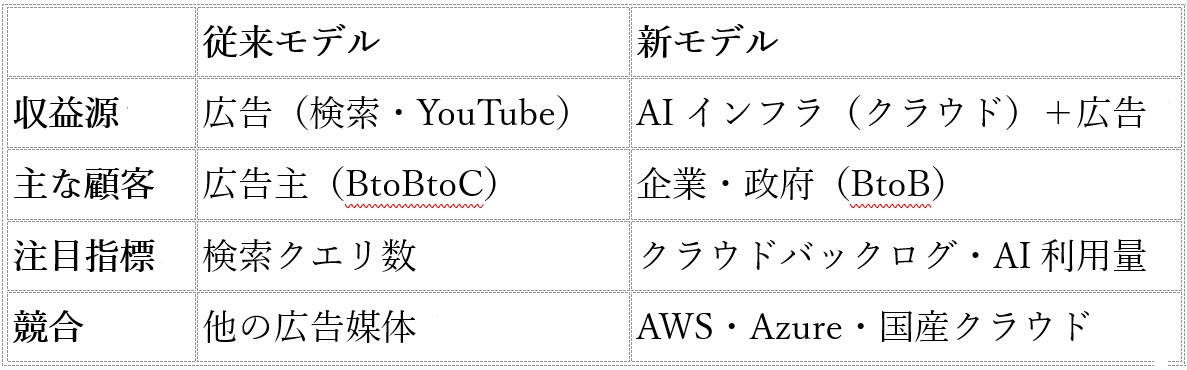
グーグルクラウドの営業利益はこの1四半期だけで66億ドルに達し、前年同期の9億ドル超から急拡大した。売上に占めるクラウドの比率も着実に上昇しており、広告依存からの脱却が財務数字にも表れてきた。
しかし見逃せないのが、設備投資(Capex)の規模だ。アルファベットは2026年通年の設備投資を1800〜1900億ドル(約28〜30兆円)と上方修正した(インターセクト社買収分を含む)。2025年の実績914億ドルから、ほぼ倍増する計算だ。Q1だけで357億ドルが投じられており、1四半期で日本の代表的な電機メーカー数社分の年間設備投資を超える額を使い果たす。
この投資規模は他のハイパースケーラーを凌駕する。アマゾン(約2000億ドル)とともにアルファベットは業界の基準値を塗り替えている。ピチャイCEO自身が「夜も眠れない問題」として挙げたのが、電力・土地・サプライチェーンのボトルネックだ。「今年はずっと供給制約の状態が続くと予想している」——この言葉は、需要がいかに旺盛かを裏返しで示している。
ITジャーナリスト・小平貴裕氏はこう評する。
「バックログが4600億ドルを超えたことは、企業のAI基盤としてのグーグルへの信頼を示している。だが年間設備投資が利益を大幅に超えるこのモデルは、成長が鈍化した瞬間に財務的な圧力が急増する構造的リスクを内包している」
CMAが本当に狙うのは「検索支配」と「AIデータ権」の切り離し
規制当局の真の狙いは、もう一段深いところにある。
CMAが厳格に要求しているのは、「コンテンツのオプトアウトを選んだ出版社の検索順位を下げてはならない」という点だ。これは一見当然の消費者保護に見えるが、その本質はグーグルが検索でもつ支配的地位を、AIデータ調達の強制手段として使う慣行を断ち切ることにある。
現状のグーグルは、ウェブクローラーで収集したコンテンツをAIオーバービューや生成AIモデル(GeminiやVertex AI)の学習・グラウンディングに活用している。CMAは「グーグルの市場支配力があるがゆえに、出版社には事実上の拒否権がない」と指摘する。リサーチ会社Seer Interactiveの調査(2025年11月)によれば、AIオーバービューが表示された情報系クエリのオーガニックCTR(クリック率)は2024年半ば以降で61%低下しており、コンテンツ制作者の収益基盤を直撃している。
CMAの提案には「グーグルが第三者スクレイパーを通じてオプトアウト済みのコンテンツを迂回取得することも禁止する」条項も含まれる。これが実装されれば、グーグルの「AIインフラ地主」としてのコアな強みに、初めて実効性を持つ法的な歯止めがかかる。
「検索での支配力とAIでのデータ優位が連動している限り、規制の効果は限定的だ。この2つを制度的に切り離せるかどうかが、グーグルの市場構造に対する規制の真の試金石になる。EUがDMAでやっていることと同じ方向性だが、CMAのアプローチはよりデータの権利保護に焦点を当てている点で注目に値する」(小平氏)
日本企業が直視すべき「データ格差」の正体
今回のアルファベット決算が示す冷徹な事実は、AI時代の富が「インフラとデータを持つ者」に急速に集中しているということだ。
グーグルの広告事業を支えているのは、世界中のメディアや個人が日々生み出すコンテンツだ。日本の報道機関、ブログ、ECサイト、自治体ウェブサイトのデータも例外ではない。これらが検索データベースの素材となり、AIオーバービューを通じてグーグルの収益に転換されている構造は、英CMAが問題視している構造と本質的に変わらない。
しかし英国や欧州と比較したとき、日本にはAIデータの利用に関して出版社・コンテンツ制作者が対価を交渉するための法的枠組みも、集団的な交渉主体も、いまだ十分に整備されていない。
「オプトアウト義務化」を単なるコンテンツ権利保護の話と見るか、あるいはデータを「売る」ための交渉テーブルを設けるための制度整備と捉えるか。この視点の差が、今後のデジタル産業政策における日本の立ち位置を大きく左右する。
AI時代の覇者は、より多くのデータを、より低コストで、より継続的に取得できる者だ。アルファベットの決算は、その競争がすでに「資本の規模」だけで決まる段階に入りつつあることを示している。問われるべきは、日本のメディア・企業・政策立案者が、このゲームのルール形成にどこまで積極的に関与できるかである。
(文=BUSINESS JOURNAL編集部、協力=小平貴裕・ITジャーナリスト)


RANKING
RELATED POSTS





ニューアングル



