アナリティクスと似た意味の言葉に、「データサイエンス」があります。日本ではむしろ、そちらのほうが一般的かもしれません。データサイエンスには学術的な語感がありますが、アナリティクスはむしろ実務的な感じがします。ともかくその基盤になるのは、データベース技術などを除くと、統計学と機械学習(人工知能の分野で発展したデータ解析手法)です。統計学が基盤にある点は、従来のマーケティングデータの解析と同じです。
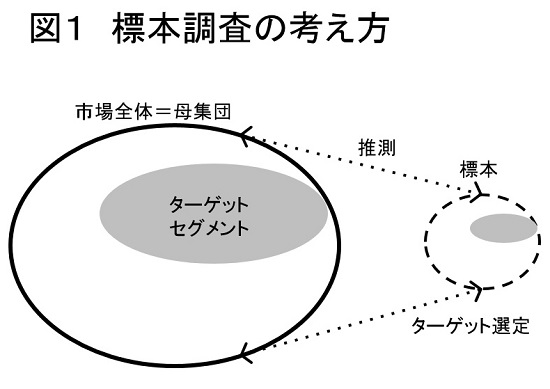
統計学(特に推測統計学)の基本は、標本から母集団の性質を把握することです。たとえば、ランダムに選ばれた1,000人の標本から、自社製品の購入者が30%いるという調査結果が得られたとします。では、日本の消費者全体(母集団)での購入率はどれくらいになるか? それを明らかにするのが統計的推測です。これは、全体の性質を知って、セグメンテーションやターゲティングに役立てようとする点で、トップダウン型発想にしたがっています(図1を参照)。
ビッグデータは市場全体を網羅したデータなので、こうしたトップダウン型アプローチがますます進展すると思われるかもしれませんが、筆者はむしろ逆だと考えています。多くのビッグデータは確かに大規模ですが、母集団を代表させるべく集められたデータではありません。その特徴はむしろ細部に関する詳しさにあり、そこで重要になるのは全体ではなく、部分なのです。そのことについて、以下述べていきたいと思います。
ボトムアップ型アプローチとしてのデータマイニング
ビッグデータとかデータサイエンスとかいう言葉が登場するはるか以前に、「データマイニング」という言葉が普及しました。マイニングとは採掘のことで、データという山に眠る金脈を掘り起こすための手法群です。そのなかで実務家が最も期待した手法のひとつが、マーケットバスケット分析(アソシエーション分析)です。巨大かつ詳細なデータから、同時に起きがちな事象を拾い出してくる手法です。
その「事例」としてよく挙がるのが、平日の夕方に男性が紙おむつとビールを併買する傾向が発見されたというエピソードです。それが事実であったかどうかはともかく、わかりやすい例なので重宝されてきました。この例にもとづいてバスケット分析を簡単に紹介すると、それは図2にある「確信度」と「支持度」の両方を基準に併買パターンを見つける手法だといえます。
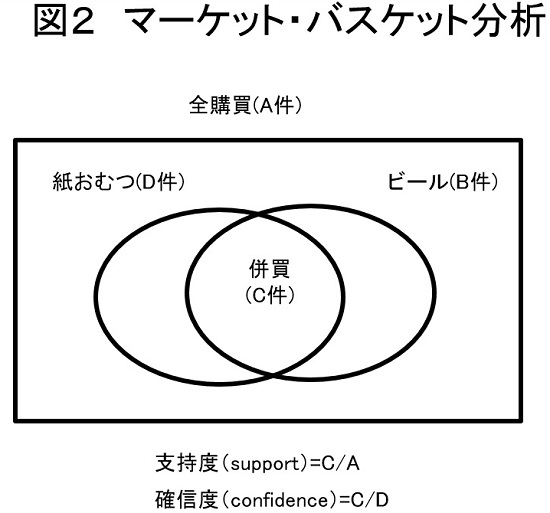
確信度とは紙おむつを買った男性が同時にビールを買う条件付確率で、支持度とはそうした併買が全体の購買のなかで起きる確率です。確信度が高いと紙おむつを買った男性にビールも買わせるプロモーションが成功しそうですが、支持度が一定の水準にないと、併買が促進されてもたいした売り上げになりません。したがって、一定の支持度を満たす範囲で、確信度がより高い併買パターンに注目することになります。
では、支持度はどれくらいあればいいのでしょうか。