現在の第3次AI(人工知能)ブームは2012年頃に立ち上がりました。間もなく10年になります。過去半世紀、さまざまなIT系のbuzz word (皆が口にする目標のようなスローガン)が各々のブームを牽引してきましたが、10年もの間、ブーム、熱狂が続くのは異例のことです。
1980年代末から92年頃にかけての第2次AIブームは急激に盛り上がったものの、妥当なコストで本格的に実用になるシステムができずに急速に凋(しぼ)んだといえます。今回は毎日のように新たなAIのブレークスルーや活用事例が報道され、実際にスマホ内部やクラウド上の何百種類ものAIに皆がお世話になっているため、単なるブームで終わらないことは確実です。
第3次AIブームの前半数年は、猫を見分ける画像認識が起爆剤となり、画像認識・文字認識、音声認識、そして強化学習、転移学習の併用で実用化が進みました。2017年頃から急発達をはじめ、ブームの後半を牽引してるのが自然言語処理です。2段ロケットだから10年続いたとみることもできるでしょう。自然言語処理のブレイクで、翻訳はもちろん、要約、対話、絵の読み解きなどが高性能化してくると、その仕事(ホワイトカラー業務)、生活(コミュニケーション全般)へのインパクトは画像認識の比ではありません。
機械翻訳は当たり前に使えるようになっている
深層学習というのは、入力と出力の間を数十億本とかの線で結んでさまざまな特徴を変換する仕組み(関数)です。そこで、理屈(文法)は返上して、だんだん長い単語列と、別の外国語の単語列を入出力に大量に並べて学習させれば、それっぽい対訳を生成できるんじゃない? とやってみたらできちゃった、というのが最近の機械翻訳(ちょっと乱暴な表現ですが)。文法よりも膨大な量の知識になるコロケーション、すなわち、自然な語の選び方やつながりを深層学習が覚える。Google翻訳も数年前に突然、精度が飛躍的に向上しました。
しかし、明らかにそれを超える、何か常に自然な文脈を生成してくれるのが、 DeepL という十数か国語間の翻訳システムです。必ずしも正解とは限りませんが、ほとんどの場合に明らかにGoogle翻訳より自然で、精度も高いです。DeepL に比べると、Google翻訳の翻訳結果は、まるで外国人が書いたような不自然さを感じる頻度が桁違いに多いです。
とはいえ、自分がある程度以上できる外国語の場合は、DeepL で1回訳しただけで若干の手直しで使ってもいいですが、心もとないとき、そして、知らない外国語の時は必ず、逆方向に翻訳したり、日本語だけでなく知っている外国語、英語などに翻訳して、決定的に意味が違っていないかのチェックは必要です。逆方向翻訳にGoogle翻訳や、中国語なら百度(Baidu)翻訳など、別の翻訳を使うのもいいでしょう。いずれにせよ、一昔前には想像すらできなかった高精度で、桁外れに実用的になったのは深層学習のおかげです。
読解力をある程度備えたAIの台頭
しかし、これらの翻訳システムは、ほぼまったく文章を理解していない、といっても過言ではありません。それなのに、なぜ外国語の初学者を凌駕する翻訳ができるかといえば、過去の翻訳、すなわち入力単語列と出力単語列の対応関係のベストプラクティスを大量に覚えているからです。量は力。ただ、いきなり入力単語列と出力単語列を(複雑に)対応させているので、途中の「理解」「意味を把握」というところをすっとばしているのがミソ。
一方、2017年にデビューしたBERTや、その数千倍規模の学習で精度をあげた2020年夏のGPT-3は、通常の人間の能力を超える「読解力」を発揮しています。読解力というのは、ずばり米国の大学の国語、すなわち、英語の入試問題で穴埋めや代名詞の指し示す先の言葉を正しく当てたり、要約したりという文章題を解く課題です。
GoogleのBERTが、とくに読解専用のチューニングもせずに、ほぼ自動生成した正解データ(穴埋めに出されそうなように文章の一部を隠したり文間のつながりを自動生成したりして入出力の対応をつける)を大量に学習さし、穴埋めを解けるようになったり、自然な文の生成ができるようになりました。
2018年10月に、完全一致でも、部分一致(部分得点)でも、優秀な人間の受験生の点数を上回ってしまいました。なお、読解専用の仕組みでないというのは、汎用の双方向トランスフォーマーという新世代の深層学習を用いているということです。自然言語処理における大成功を踏まえて、このような新世代の深層学習が、先行していた画像認識・分類のほうでも高精度化や、学習時間の短縮に使われるようになっています。
Open AIという組織が開発したGPT-3では、BERTの数千倍の規模となりました。1回の学習に電気代が5億円かかるという、大学や普通の企業の研究所では再現不可能なコストをかけて膨大な量の英文を学習させています。その結果、GPT-3がSNSアカウントに毎日投稿し、コメント付けた人と新しい対話をどんどん進めながら、2020年の3カ月間、誰も機械の執筆だと気づかなかったというのです。これは確かに驚くべきことです。人の言い回しはもちろん、その内容、要約の仕方など、膨大な量の過去の正解データを繋ぎ合わせて合成するAIによって、見事にフェイクできました。
文章を数値化することでマーケティングにじわじわ革命
さて、大学受験で良い点が取れても、商売で売り上げ、利益を出すことはできません。言葉を操ることで、あらゆる業界で直接商売に貢献するのは営業、マーケティングの仕事でしょう。例えば、8月31日の拙記事『真のDX推進を実現する正しいAI導入のコツ…』の「日本語などの自然言語の解析、分析もできそうでできていなかった」でご紹介した、ビジュアル類似検索機能を使うと、大量のクチコミ(多ければ多いほどマーケティングには嬉しいご利益があるけど作業時間は増えません!)の類似ランキング結果から、色のついた自分たちの言葉(企画書等からコピペ)の周辺に、似た意味合いの【お客様の言葉】をたくさん見つけることができます。
え、なんでそんなのが重要ですって? だって、商品やサービスを探してWebで検索するのはお客様です。そのお客様が使う言葉を予め知っておけば、いわゆるオーガニック検索でも順位を上げられるし(SEO=Search Engine Optimizationといいます)、広告キーワードにも、最近お客様が使い始めた言い回しを採用できるではないですか! こんなAI併用で、お客様の言葉をいち早く収集、ランキングできた会社は間違いなく、ライバル企業を出し抜くことができます。
前回ご紹介した「個人情報やNGフレーズを自動的に検出」するAIも自然言語処理AIを応用したものです。ミスや故意により、メール文章などから情報漏洩するのを防ぐこともできるし、公開前のコンテンツに個人情報が紛れ込んでいないかとか、法令違反のフレーズが入っていないかなどをチェックし、コンプライアンス準拠のためのコスト削減、スピードアップにつながります。
「守り」より「攻め」のための競合分析には、文章のネガティブ度やポジティブ度を各3段階(±3, ±2, ±1) と中立0を合わせた合計7段階で判定した記事の件数を、2つの分析軸でプロットし、ポジショニングマップを自動生成することで、対競合のマーケティング戦略の立案にダイレクトに貢献します。
もっとシンプルでわかりやすい事例が、文章中のさまざまな地名(ランドマーク、市区町村名等)を検知して都道府県名に展開し、クチコミ投稿の分布状況を日本地図上で眺める機能です。次の生データは、リクルート社のじゃらんで公開されていたものから日本の温泉に関するもの約1万6000件を集めたもの。内容的に、温泉の場所を示唆する手掛かりが含まれている可能性の高いデータです。
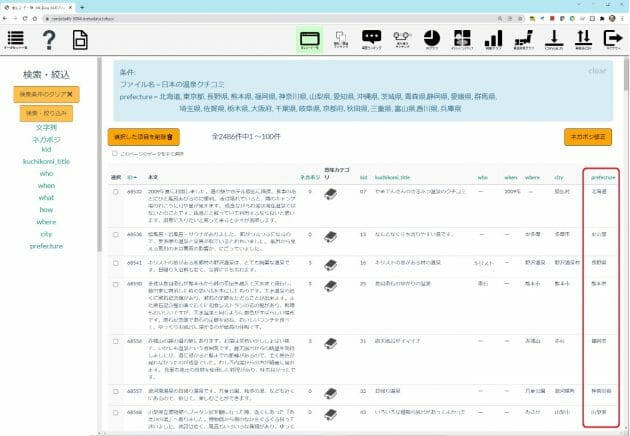
緯度経度情報や、ユーザーに都道府県名を入力させたデータが無いため、べた書きテキスト中の5W1H抽出から、知識ベースを活用して都道府県マップを全自動で生成しています。
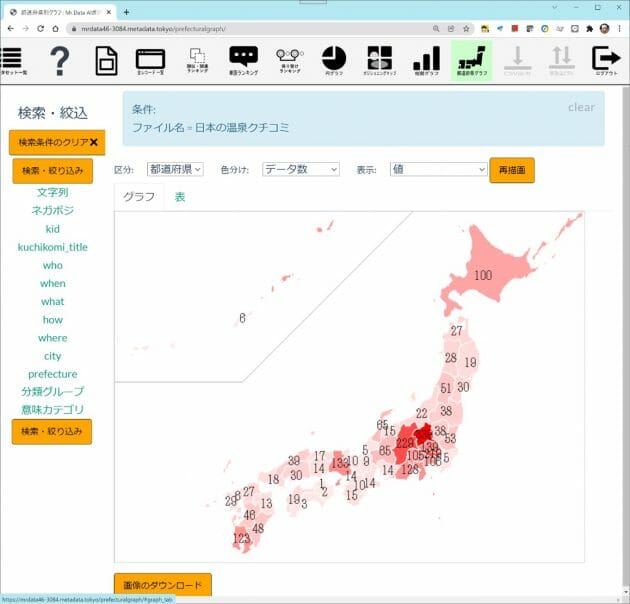
ランダムに選んだ1万6000件でしたが、草津温泉に代表される群馬や、長野、有馬温泉に代表される兵庫などの件数が多いことがわかります。このデータからは、温泉自体の良しあしや、付帯設備の良しあしについてテキストから評価値を抽出し、旅館にフィードバックしたり、数値やグラフ(ニコニコマーク vs. 悲しいマークなど)でわかりやすく消費者に文章由来の評判を見せることができるようになります。
選択肢回答、信用できますか? NPSも。
このようなお話を、同業の会社さんとしていたら、面白い! でもうちはNPS(Net Promoter Score)という、知人に同商品・サービスを薦めたい度合い0から10の11段階の選択肢と合わせて取得して活用するのに強味があって、という興味深い話を聞きました。マーケティングに使えるデータは何百、何千種類とあるでしょう。同じデータ群であっても、その料理法、使いこなしもさまざまです。
互いに補完関係にあるし、言葉の分析でマーケティングを高度化するコミュニティをもっともっと大きくしよう、ということで意気投合。このマーキットワンさんと共催セミナーを開催することになりました。直近で恐縮ですが骨子をご紹介です。
(文=野村直之/AI開発・研究者、メタデータ株式会社社長、東京大学大学院医学系研究科研究員)
■開催概要
タイトル:マーケティングと自然言語分析
~顧客満足度向上の為のNPSの活用方法~
日 時:2021年12月22日(水) 14:00-15:00
■ウェビナー内容
1. 開会(5分)
2. マーケティングと自然言語分析(野村) 20分
3. NPSを活用した顧客体験の改善活動(望月、北山)20分
4. 「AIポジショニングマップMrData」で自由回答とNPSの乖離を分析(野村)5~10分
5. NPSに特化した顧客満足度ツール「Markitgauge」について(石井) 5~10分
6. 質疑応答




RANKING
RELATED POSTS



ニューアングル



